Microsoft Copilot in Excel Gets Smarter: Reusable Skills, Live Data Connectors, and Full Edit Transparency for Finance Teams
If your daily grind involves endless spreadsheets, repetitive calculations, and manual data entry, there is finally some good news. Microsoft Copilot in Excel has received a significant upgrade designed specifically for finance professionals. The new features focus on three pain points: automating repeatable tasks, pulling live data from trusted sources, and maintaining a clear audit trail of every change made by the AI. This update promises to transform how teams handle financial modeling, closing processes, and variance analysis.
What Are Copilot Skills and How Do They Work?
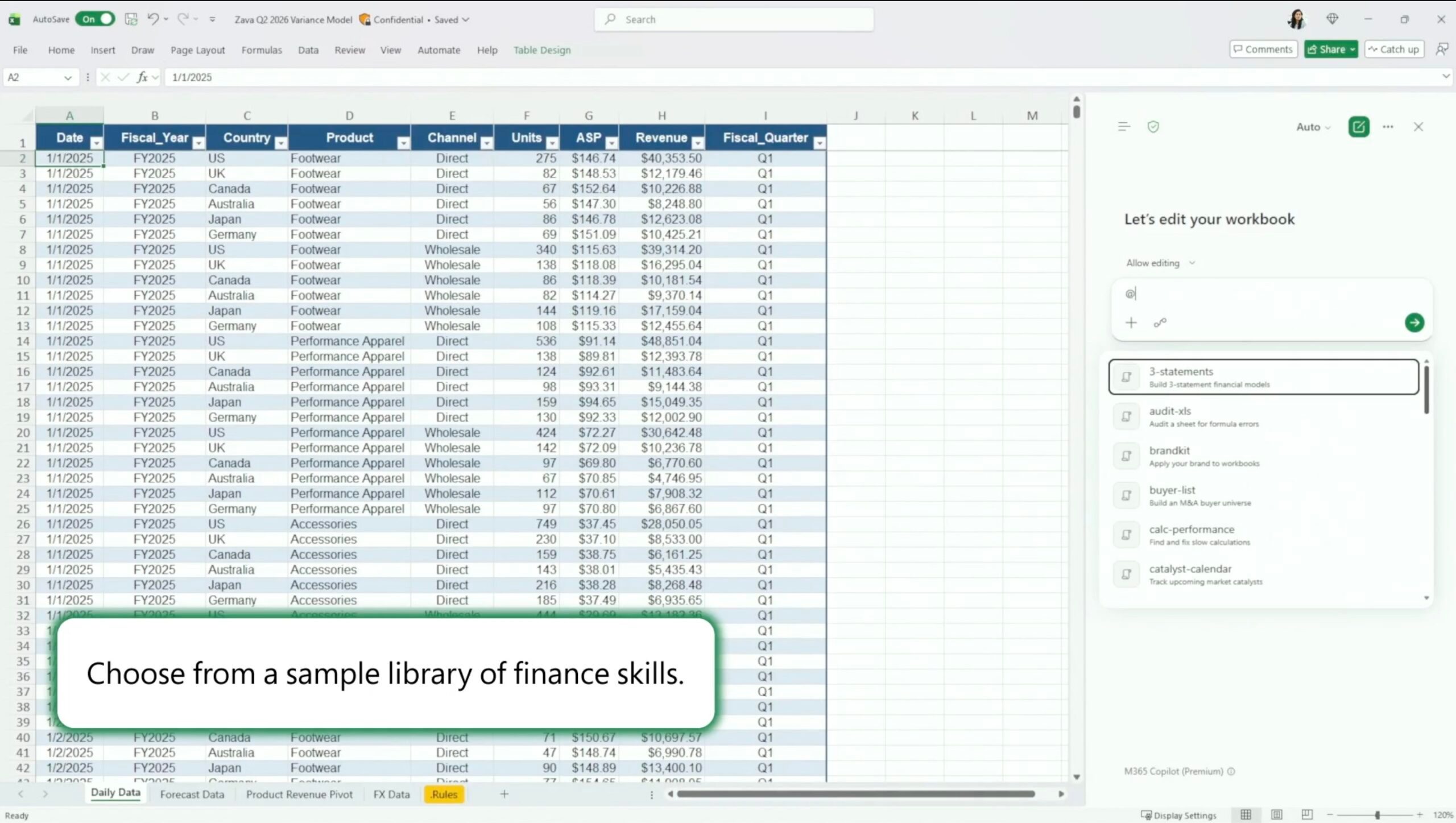
The headline feature of this update is called Skills. Think of it as a way to teach Copilot your specific workflow once, and then reuse it across any workbook. Instead of typing the same detailed prompt every time you need to build a discounted cash flow (DCF) model or compile a monthly report, you simply save a SKILL.md file in OneDrive. From that point on, Copilot follows your instructions, formatting, and structure automatically.
Microsoft also offers prebuilt finance skills for common tasks. For those who need something more tailored, building your own skill is straightforward. Later this year, partners like LSEG, Ramp, Rogo, and Vena will sell their own skills through the Microsoft Marketplace. This ecosystem could turn Copilot into a central hub for specialized financial analysis.
How to Get Started with Custom Skills
To create a custom skill, you write a SKILL.md file that describes the steps, formulas, and outputs you want Copilot to follow. Save it in a designated OneDrive folder, and Copilot will recognize it the next time you open a relevant workbook. This approach eliminates the need to repeat instructions, saving hours each week for finance teams who deal with recurring reports.
Live Data Connectors: Real-Time Numbers Without Copy-Paste
Another major enhancement is the ability to pull live data directly into Excel through new connectors. Microsoft Copilot in Excel now integrates with CB Insights, Daloopa, FactSet, Morningstar, PitchBook, and S&P Global. These join the existing LSEG and Moody’s connectors that were introduced in May. The result is less time spent copying and pasting data from external reports and more time analyzing current numbers.
It is worth noting that some of these connectors require a separate subscription. However, for finance teams that rely on these data sources daily, the convenience and accuracy of live data can justify the cost. This feature ensures that your models are always based on the most recent information, reducing the risk of stale data skewing your analysis.
Full Transparency: Tracking Every Edit Copilot Makes
Trust has always been a challenge when using AI in finance. Microsoft addresses this with a new Plan with Copilot mode. Before Copilot makes any changes, it lays out exactly which ranges, formulas, and assumptions it will touch. You can review and approve these changes before they are applied. After the edits are made, the Show Changes pane clearly distinguishes between changes made by Copilot and those made by human teammates.
This level of transparency builds on Excel’s existing Agent Mode and comes shortly after Microsoft’s acquisition of the finance AI startup Fintool. Together, these moves signal that Microsoft is serious about making AI trustworthy for financial work. For auditors and compliance teams, this traceability is a game-changer.
Availability and Rollout
These updates are live now for Microsoft 365 Copilot customers using Excel on the web, Windows, and Mac. Custom Skills are rolling out to all users over the next month. If you are a finance professional who spends hours in Excel, now is the time to explore these new capabilities. For more on how AI is transforming office productivity, check out our guide on best AI tools for productivity.
In addition, you might want to learn about Microsoft Copilot vs ChatGPT for a broader comparison of AI assistants. And if you are new to Excel automation, our Excel formulas cheat sheet can help you get started.
Overall, this update makes Microsoft Copilot in Excel a more powerful and reliable assistant for finance teams. By automating repetitive tasks, integrating live data, and providing full edit transparency, Microsoft is addressing the core needs of financial professionals. The future of spreadsheet work looks faster, smarter, and more trustworthy.











 CyberSecurity4 months ago
CyberSecurity4 months ago
 CyberSecurity4 months ago
CyberSecurity4 months ago
 CyberSecurity4 months ago
CyberSecurity4 months ago
 Social Media4 months ago
Social Media4 months ago
 Infosecurity4 months ago
Infosecurity4 months ago
 CyberSecurity4 months ago
CyberSecurity4 months ago
 How To3 months ago
How To3 months ago
 CyberSecurity4 months ago
CyberSecurity4 months ago